machine, anthropology, big data, pivot table
What is Machine Anthropology?
Ajda Pretnar
Jan 29, 2020
For those unfamiliar with the field, cultural anthropology is the study of human cultures, practices and habits in a holistic and comparative manner. Its core method is ethnographic fieldwork, which means researchers spend a long time in the field with their subjects, live with them, talk with them, socialize with them, and observe relationships and behaviours. But recently, anthropology has begun to use also machine learning and data mining as a part of its method. The subdiscipline is called computational anthropology (combining ethnographic fieldwork with big data) or machine anthropology (ethnography as big data).
Related: Data Mining for Anthropologists
Copenhagen Center for Social Data Science (SODAS) held a conference on machine anthropology just a few days ago. It was inspiring to see how the humanities benefit from computer sciences and vice versa! There, I presented my PhD research of sensor data from a smart building and used Orange to show how to detect patterns of behaviour in such data.
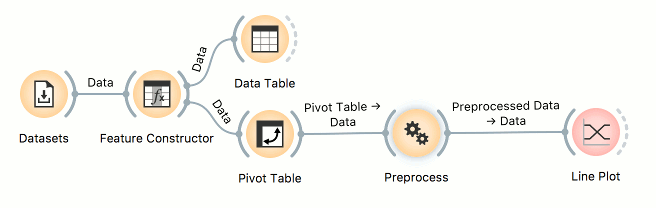
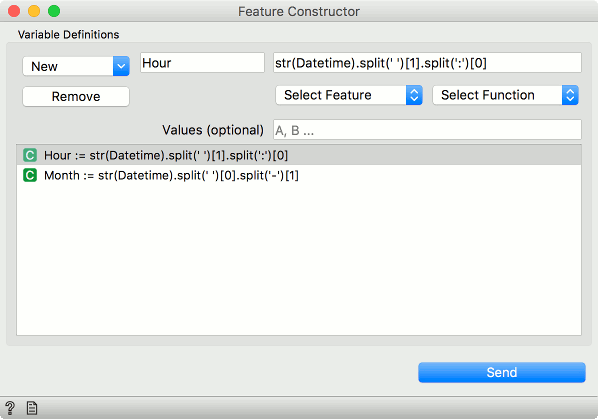
Here I will show a different example by using a publicly available Philadelphia Crime data set that can be loaded in the Datasets widget. This data set reports crimes in the city of Philadelphia from 2006 to 2016. We will have to create two new features, one for hour of the day and one for month. In the Feature Constructor we will write two Python expressions that parse month and hour from the datetime feature.
How does our data look like now?
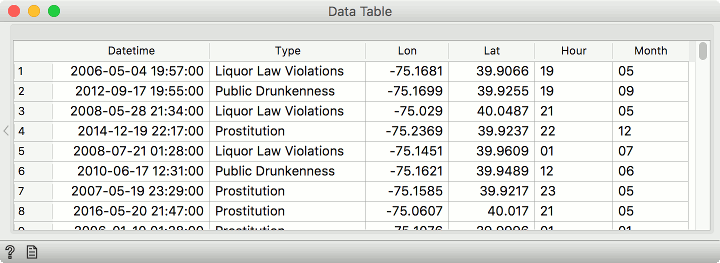
Perfect. Now say we would like to establish the frequency of crimes by the hour. We will use Pivot Table to count the occurrences of each type of crime. We set rows to type, because we are interested in the differences between different types of crimes. Then we set hour as columns. This will create a new timeseries-like data table, where each column will represent a single hour of the day. Values can be set to anything, because we will not use any special type of aggregation, but simply count occurrences of crimes.
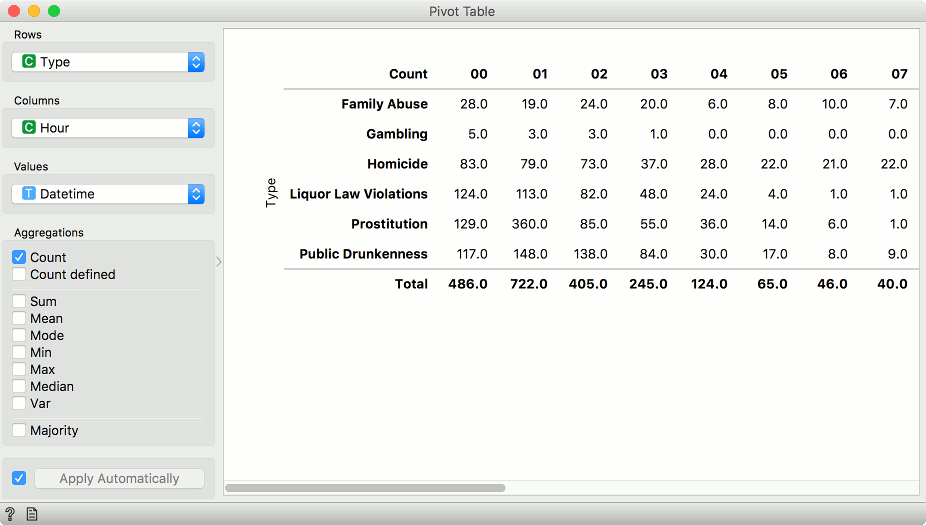
We can observe the results of the pivot table in a Line Plot. We group by type and see how crime frequencies change with respect to the hour of the day. Unsurprisingly, the liquor law violations and prostitution go up late at night. Prostitution in particular, is a very frequent crime in Philadelphia (or at least was in the time of reporting).

If we standardize the data with Preprocess (default normalization option), we see a more balanced picture, where homicides are relatively much more frequent early in the morning than at any other time of the day. Apparently, murderers are early birds.

There you are, a workflow for observing simple timeseries patterns in the data. Of course, you can create much more complicated workflows in Orange or even write a custom Python script. If you have you own examples of anthropological, sociological, or any kind of socially-oriented data analysis in Orange, we'd love to hear about it!