Download and install
Download Orange distribution package and run the installation file on your local computer. Follow installation guides for your operating system.
Download Orange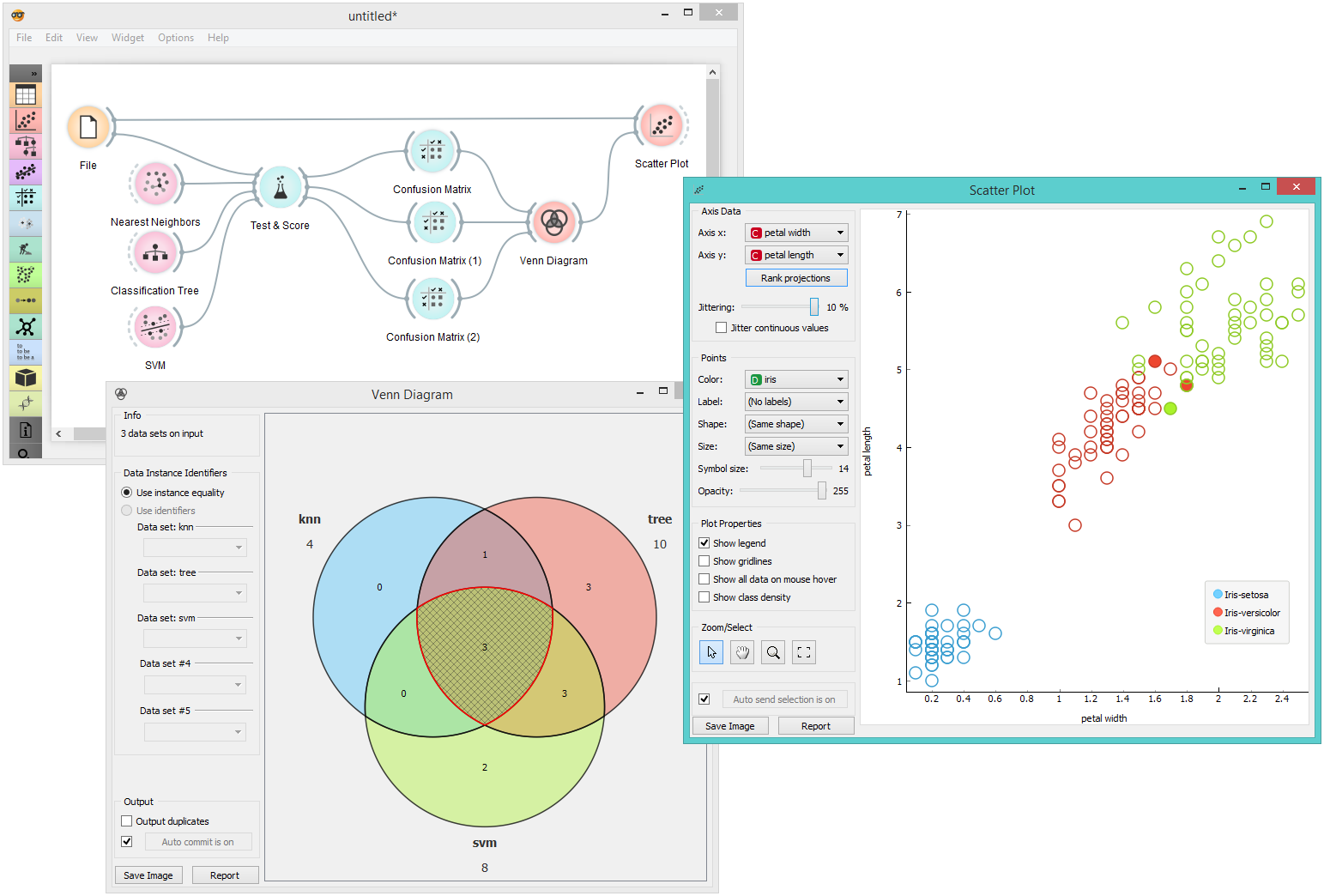
Widget catalog
Orange widgets are building blocks of data analysis workflows that are assembled in Orange’s visual programming environment. Widgets are grouped into classes according to their function. A typical workflow may mix widgets for data input and filtering, visualization, and predictive data mining. Here you can get list of all widgets available in Orange.
Widget catalog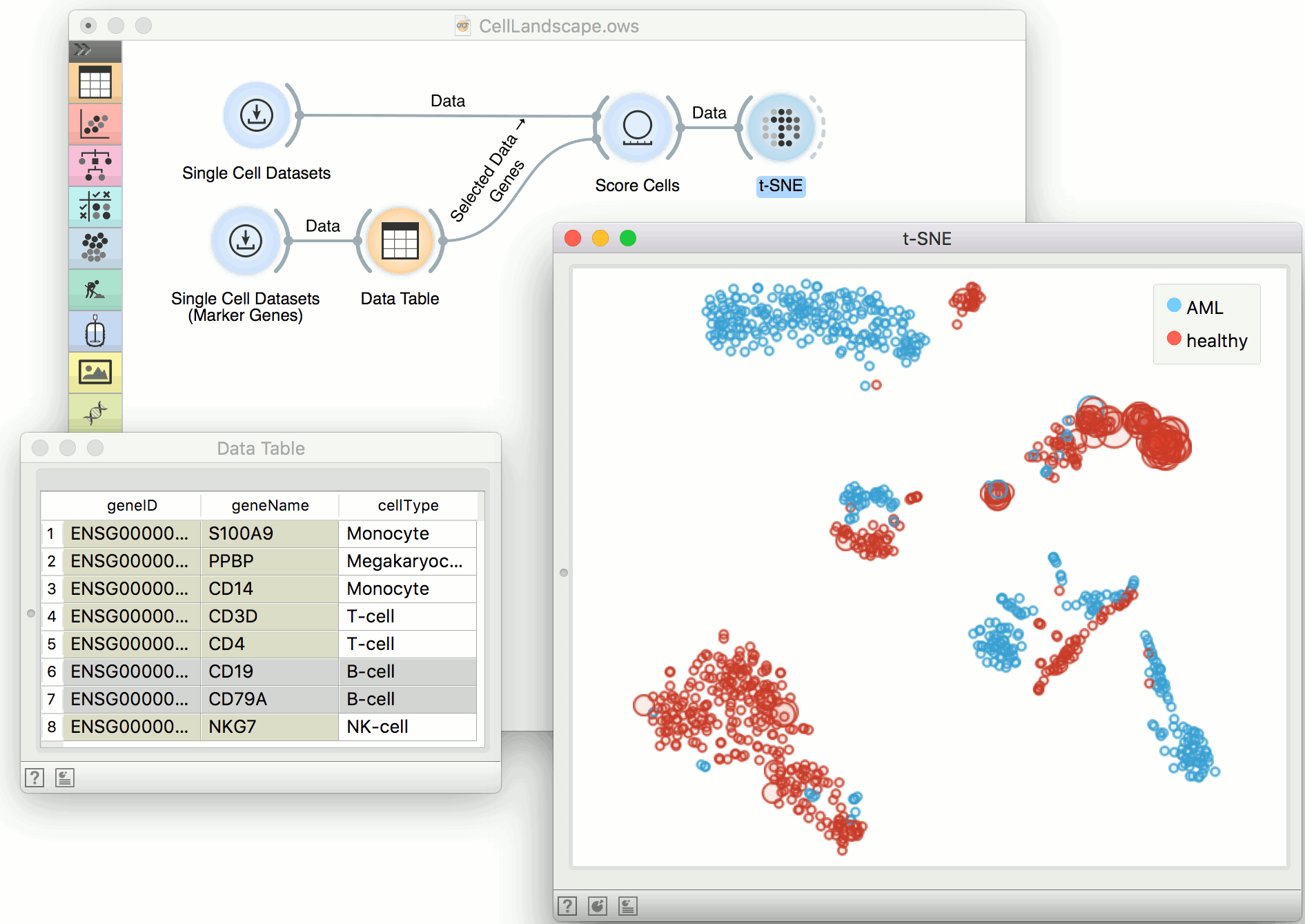
Workflow examples
Software Orange includes a wide array of workflow templates designed to help you get familiar with the application. Pick Templates on the Welcome screen to explore.
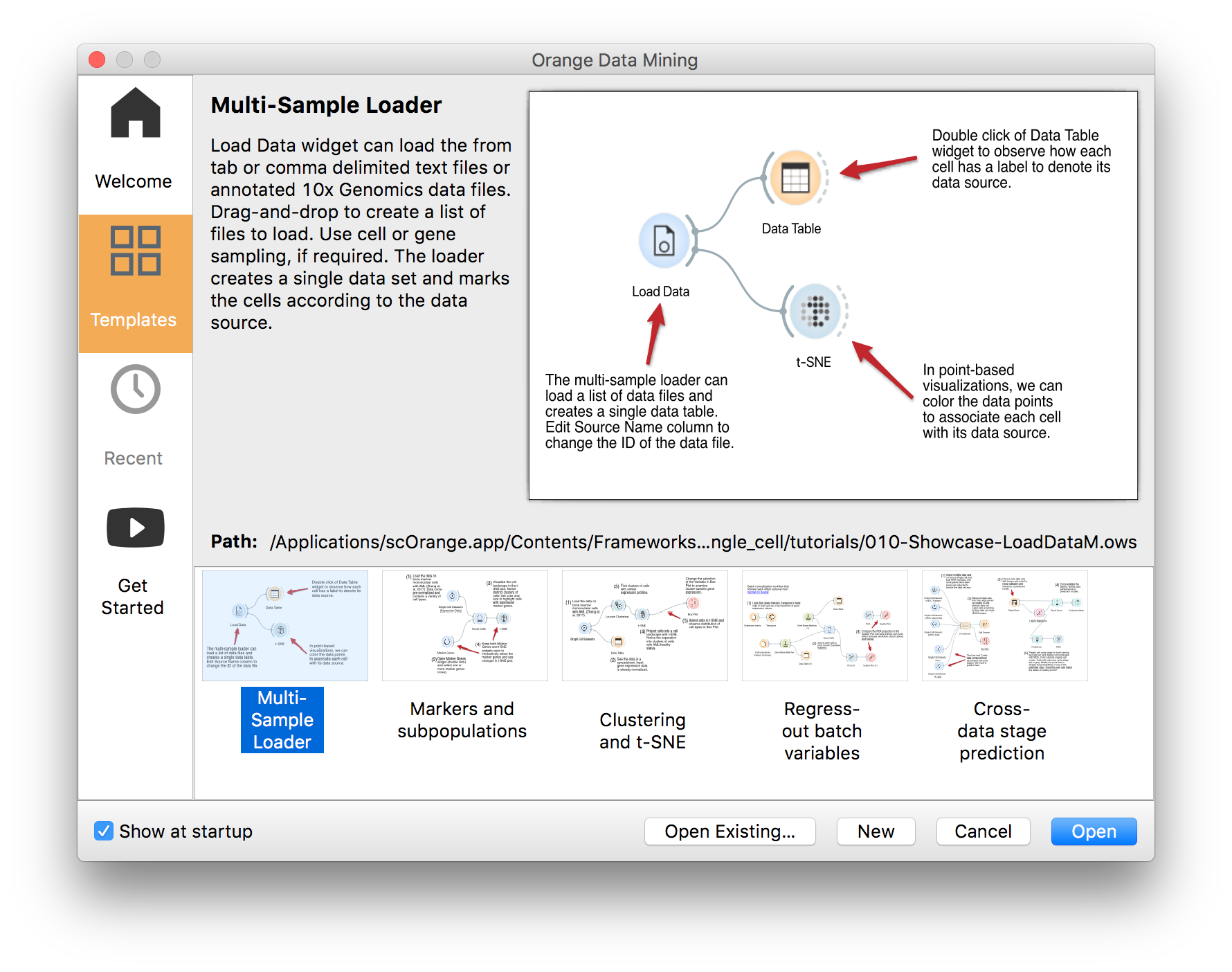
YouTube tutorials
Introduction to the Orange data mining software. Learn about the development of Orange workflows, data loading, basic machine learning algorithms and interactive visualizations. Video tutorials are available in button below.
YouTube tutorials